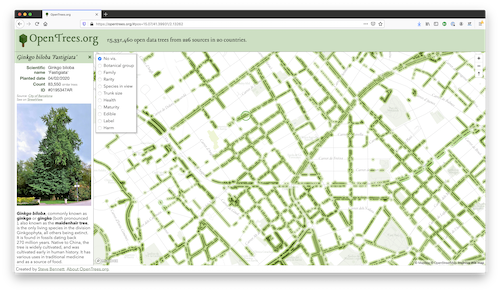
We kick off the week with another open data interview. Today I’m delighted to talk with Steve Bennet the maker of OpenTrees - the world’s largest database of municipal street and park trees.
1. Who are you and what do you do? What is OpenTrees? What got you into crowd-sourcing tree data?
I’m Steve! I’m a freelance web developer, specialising in maps - particularly Mapbox-GL-JS and VueJS. Around 5 years ago, I started getting interested in the open data that local governments around Australia were publishing. There were just a couple in my local area publishing any data, and a few of them published tree registers: detailed databases of every tree that they managed. I’d never seen anything like it.
I was starting to learn about making maps, and so I did the obvious thing and put the three tree datasets on one map, with unfortunately a large gap between them. I thought it would be cool if more councils released their tree registers, so I turned it into a public site, the first version of opentrees.org.
I started talking to local councils about publishing data (an effort which become opencouncildata.org), and sort of used it as a bargaining chip: “if you publish your data, it will go on opentrees.org, and isn’t that cool?” It was followed by a similar site for garbage collection zones: openbinmap.org, but really, there’s only so much interest you can squeeze out of garbage collection.
2. What is the goal of the project? How is it going? What are the main challenges?
The main goal is simply to be the place where all public tree registers get aggregated to. So, if you want to work with tree register data at all, you don’t need to repeat all that hard work: start with opentrees.org, and build from there. Either send a message to the OpenTrees mailing list, or at least take the source code and use that.
There are lots of fairly mundane challenges in harvesting all this data: no standards, different data formats, data that is broken in many different ways, data that is old or inaccessible, etc. Some of the faulty data is sort of hilarious: a cluster of trees around Null Island - but not exactly at 0, 0. A long line of trees from Cologne, Germany that have ended up in northern France. A few from London well off the west coast of England, and so on.
There are also subtle semantic challenges: what is exactly is the scope of data that we want? Do stumps count as trees? Shrubs? Bushes? How about trees in people’s back gardens? Or trees that were digitised from aerial imagery, with no information other than “tree here”?
A really interesting challenge is how to use colour to visualise species. There’s a pretty small range of distinguishable colours, and thousands of species - so how do you do group them? You want to make useful distinctions, but also somehow respect botanical taxonomy, and maybe other characteristics like native vs introduced. It’s challenging. My primary colour scheme uses blues and greens for Australian native trees, which is helpful for making native bushland (eucalypts, casuarinas and acaias) stand out from streets lined with European trees such as elms, oaks and plane trees. But there are compromises everywhere. I wrote a Twitter thread on this.
One of the hardest, but most rewarding challenges, is cleaning up the species data, and hence being able to link each tree record with potentially a wealth of information about that given species. But species information can be wrong in many ways, ranging from simple typos (“Sailx” instead of “Salix”), to common names in the scientific field, to outdated species names, to misidentifications. And it’s surprisingly difficult to find a relatively comprehensive list of tree species to match against.
3. You’ve worked on so many different geo tools and services. What are the main learnings along the way? Any advice for others looking to create an online geo service?
The main thing I have learnt is that the fundamentals of visualising other people’s vector spatial data are really simple. Almost all the difficulty comes from interacting with the wide variety of software and services, which implement different interpretations of standards and proprietary formats such as Shapefile which have stuck around for an unbelievably long time. I’m very grateful that standards like GeojSON have been successful, and companies like Mapbox have put a lot of effort into making spatial data work well on the web. Meanwhile, platforms like Google Maps feel like real dead-ends that don’t really develop transferable skills or allow you to combine different technologies together.
It’s hard to know where to start with advice! Read blogs. Find an interesting, manageable problem that captures your attention and try to solve it. For me, it was the challenge of building an online map of the cycle tours that my friends and I have been on - which eventually evolved into this. Use gis.stackexchange.com to ask questions, or Twitter. Join a local MapTime chapter if there is one, or look out for other local events.
Me, I have almost zero experience with Esri tools, and very little with QGIS. I do virtually everything with JavaScript, a little bit of ogr2ogr, and a couple of niche command line tools like tippecanoe. For me, getting really good at one programming environment has worked out well, rather than spreading myself thinly across different languages and too many tools. It means I’m very productive when someone asks me to quickly build a crowdsourced map of resources for healthcare workers in Polynesia, for instance.
4. What is the best way to get involved in OpenTrees development? Are you looking for contributors?
I’m definitely interested in collaborators, particularly people who have ideas for features or new directions that might complement opentrees.org. I’m not necessarily trying to build a single website that does everything tree-related, but the idea of an open tree-data ecosystem is pretty appealing. I’m working with the creator of fallingfruit.org so they can benefit from the range of data sources already present in opentrees.org (more than 220!) I would really love to hear from anyone with creative ideas for using the data.
There are also some manual tasks, like tracking down licence information and adding new sources that always need doing too.
5. What steps could the global OpenStreetMap community take to help support tree mapping?
Interesting question. My focus with opentrees.org has primarily been on harvesting data from authoritative sources such as local councils and arboretums. There is only a little bit of OSM data, from Chile. I think it could work well when there is a concerted effort in a particular area, and careful attention to species identification. The value of the data goes up a lot when you know it is comprehensive for an area - so gaps mean that there actually no trees there, not just that no one bothered to map them.
6. Our traditional closing question: in 2019 OSM celebrated its 15th birthday, so we are well into the “teenager” stage of the project. But what will it look likes when it “grows up”? Where do you think the project will be in 10 years time, both in terms of the geodata comprehensiveness but also the software and infrastructure around the project?
Interesting, and impossible, question! I got into OSM in around 2006, with a lot of enthusiasm and high hopes. I’ve been at times disappointed with the ongoing messiness of the data, and how hard it seems to standardise tagging. I imagine that in another ten years, the tiresome ambiguity around “highway=path” and “highway=footway” will be much the same, and we will still have awkwardly-named tags like “smoothness=very_horrible”. And I imagine that the front page of openstreetmap.org will continue to display a raster tiled map of dubious aesthetics, and that for most people, that one rendering will be what they think OpenStreetMap is - as opposed to the incredible community-maintained geospatial database of awesome scope that is the real output.
On the other hand, I hope that we will have better tools for using the data, which continue to improve each time I look. OverPass is powerful but hard to use, and using extracts of data is quite challenging for any OSM novices, but I can see progress happening on those fronts. And I think that as Mapbox and other OSM-based mapping platforms grow, general familiarity with the platform will grow. Within the last ten years, I’ve gone from having to constantly explain what OpenStreetMap is, to just having to correct misunderstandings. Maybe in another ten years, everyone will actually know what it is and appreciate that Google Maps isn’t the answer to everything :)
Great stuff, Steve! Congrats on all the progress with OpenTrees. Hopefully it’s the start of much more, we encourage everyone to get involved. Andof course we completely agree that Google Maps isn’t always the answer ;-)
Happy tree mapping,
Please let us know if your community would like to be part of our interview series here on our blog. If you are or know of someone we should interview, please get in touch, we’re always looking to promote people doing interesting things with open geo data.