Long time readers of the blog will recall our interview with the OpenStreetMap community in Nicaragua. In that interview there was some discussion of the difficulty of Nicarguan addresses - or “place descriptions”. An example cited was an address like “from the “Little Tree” 250 meters west.” Addresses like this are almost impossible for normal geo search services to deal with.
Today I am delighted to have the chance to speak with Juan Gutiérrez, one of the makers of search service Ojtli that is working to convert these direction descriptions into meaningful directions.
1. Who are you and what is Ojtli? What prompted you to start the project?
This is Juan Gutiérrez, Computer Engineer and fan of the geothings. Ojtli (means “road” in Nahuatl, an indigenous language) Is the project that aims to achieve the interpretation and geocoding of non-standard addresses, such addresses are those which are not based on Streets + House number schema, instead they describe the route to the location from a reference, imagine this like treasure map indications: From point X (reference), move Y steps(meters, blocks, etc) to the Z direction (cardinal point)
I started to take on the project as a way to find a solution to a problem no one was able to solve before, because in my head there was technological solution to it. Also because I thought, that like me, there were people that would like to know how to go to a place, what distance is to it, etc without knowing the place in advance and without going to scroll in a map every time. There was also some sort of envy to other countries that take for granted that they can do this.
2. How many people are using the service? What is the main use case?
Unfortunately the project haven’t gotten much traction, a few requests a day, with days with spikes. I may be the one to blame because haven’t put much effort into SEO or UX. The use case is as simple as getting the geographical location of an address, but then what you can do with that info is the interesting, from simple uses like knowing how far is such location for the common people, to industry scale uses in the delivery and logistics companies for example.
3. How does it work? Can you share any of the technical details?
The algorithm does two main tasks:
1. Interpretation: we have two ML models to classify and identify entities in the addresses. Classification is necessary because depending on the type we will apply different actions in the subsequent algorithm, NER is used to identify the relevant parts from the addresses, such as reference, displacement segments, etc. We had to came out with our own heuristics in order to classify and identify the entities because bibliography about our addresses is basically non-existent, more info can be found here. Also applying these models allow us to ask the user only a single textfield, instead of asking several different ones, we felt that would be error prone and an UX barrier.

2. Geocoding: Once we have the type of the address and the relevant parts, a number of functions will further refine the information, e.g: from the segments such as “3 blocks to the east”, we need to get the info for the distance (3), the unit(blocks equivalent to approx. 100mts), and the orientation (east). Fortunately those segments are treatable with regular expression in order to get that information. Then depending on the address we follow the instructions, e.g the most common case is a structure like: (Reference) + Segments[], so we look out for Rerefence (POI) in our DB and we get its geopos, then we apply the displacement segments and we got the new geopos which would be the geopos of the address.
That stage of applying segments is at the moment an approximation, because of several reasons:
- streets are not exactly aligned to the described orientation, the text may say “north” but the street, could be any where to -45degrees to 45degrees, beyond that it may become east or west
- the units, most of the time blocks, are not the same spacing, they could be anywhere between ~50m to ~200m, less that 50m and probably they would be called “andenes”[platforms], more that 200m and they are probably not using blocks but a straight number like “250mts east”
- the streets may not be straight lines, Managua is the main example because suburbs closed neighborhoods became part of the main city hence inheriting curved streets, all of that adds up a margin of error which we have calculated is ~80m in average.
4. What are the craziest “addresses” you have seen?
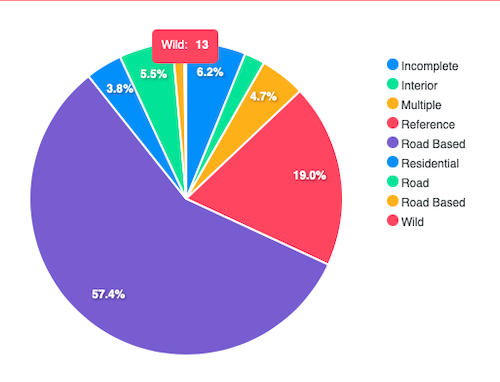
We actually have defined a type for “craziest” addresses, we called them “wild”, however we don’t aim at geocoding such addresses, one reason is they are, well, “wild”, meaning it would be difficult to find an algorithm to actually “translate” its position, one of such addresses is this:
“from the entrance of the Montecielo residence, turn left, third entrance on the left”
As you can see there, the segments are almost unintelligible, you must be physically in the location to know where to go. Other reason we don’t work with such addresses is that they are only found in ~0.2% of our records, it’s the lowest count of the types we identify, we are talking here about “official” datasets, like the list of a Bank’s ATMs, we think it’s very unlikely you will give such type of address for “official” purposes such as getting a delivery or signing papers.
5. Right now the service is focused on Nicaragua, but you believe it has applicability in other Spanish-speaking countries in Central America. How would you go about extending it to other countries? To what extent are the “addresses” or “location descriptions” limited to the local culture?
First I’m 100% certain, that we can easily extend the current algorithm to our neighbours Costa Rica, take a look:
“500 meters north of the Automarket of Santa Ana” (Costa Rica)
“From Santa Ana Municipal Stadium 3 blocks south” (Nicaragua)
For me (and hopefully for everyone) is obvious these are basically the same way to describe an address just using a different order, the same structure of Reference + Segments[] is kept, probably we cannot use the exact same model, but I think many of the heuristics we use for Nicaragua, can be used for Costa Rica. In a broader perspective, I consider these addresses as “descriptives” and I’ve read complains in social networks about those type of addresses being used in several countries like Mexico, Colombia and specially Puerto Rico so I think we are onto something that by being generalized can serve to other countries.
About “local culture”, despite many mockering and making fun of them, there are also people recognizing them as part of their culture and those who find in them more value than just determining a location, I’m on the praticality side of things, and I recognize these addresses are hihgly inneficient in a globalized world, but I think goverments can do better than forcing people into using a completely unrelated nomenclature that doesn’t inherit culture and/or tradition. One idea that has been proposed is naming some streets after references that were there, for example one street in Nicaragua could be named after the “Little Tree” reference, the “Little Street avenue”
6. How many people are working on this? Is the project open source? Is it using open data? What is the best way for people to get involved and contribute?
It’s only me in the engineering role, and my wife helps me to geolocate references, other relatives have also help on geolocate references specially those that doesn’t exist anymore. The project is not open source at the moment, but I’m not ruling out it will become OS in the future. Right now I’ve only used data from OSM to map a couple of Roads, so I can find an address like “Km 5.5 in the Road to Masaya”. I found the data regarding buildings not suitable for my use in the way it’s represented in OSM, however I noticed that we can now create pins in the map, so I may revisit that data in the future. Unfortunately right now there’s not a direct way for people to get involved, other than using it and helping me popularize it, but I’m trying to contact the local OSM community so we may work in couple of mapathon ideas that the project can contribute to OSM and also Ojtli can read from OSM in the future.
7. What new developments can people expect around Ojtli in 2021? Where is the project heading?
Our technical goals are improving the accuracy of results and improving the NLP models to cover edge cases. We also want to start introducing some sort of format for example having References always at the start, etc, we want to do this automatically by showing the results in that format, not asking the user to do it in advance. That ties into the ultimate goals of the project which are, in first instance, ignite the conversation about our addresses, the history behind them, and the steps we must do to move out from them into a better way, and secondly we would like it to become the tool for translating the current nomenclature into that new format we the people will agree to use.
Many thanks, Juan, for sharing the Ojtli story. Good luck takign the technology forward, and I hope this interview leads to a few more collaborators. It would be fantastic to find a way to integrate with the local OpenStreetMap community.
Anyone who would like to learn more should attend the May 12th Geomob Online event where Juan will be presenting about this project.
Happy geosearching,
Please let us know if your community would like to be part of our interview series here on our blog. If you are or know of someone we should interview, please get in touch, we’re always looking to promote people doing interesting things with open geo data.